The Research ‘Site’
Top 500 Search Terms: ‘Site’ Description
This chapter continues the examination of the data gathered from the “Top 500 Search Terms” newsletter that was introduced in the first chapter. A newsletter is an unconventional research ‘site’. There is no specific site in either the sense of a specific point of interaction or as a site of immediate cultural activity. The “Top 500 Search Terms” is received as a weekly newsletter that consists primarily of a list of 500 search terms that is emailed to its more than 88 000 subscribers (Figure 3).
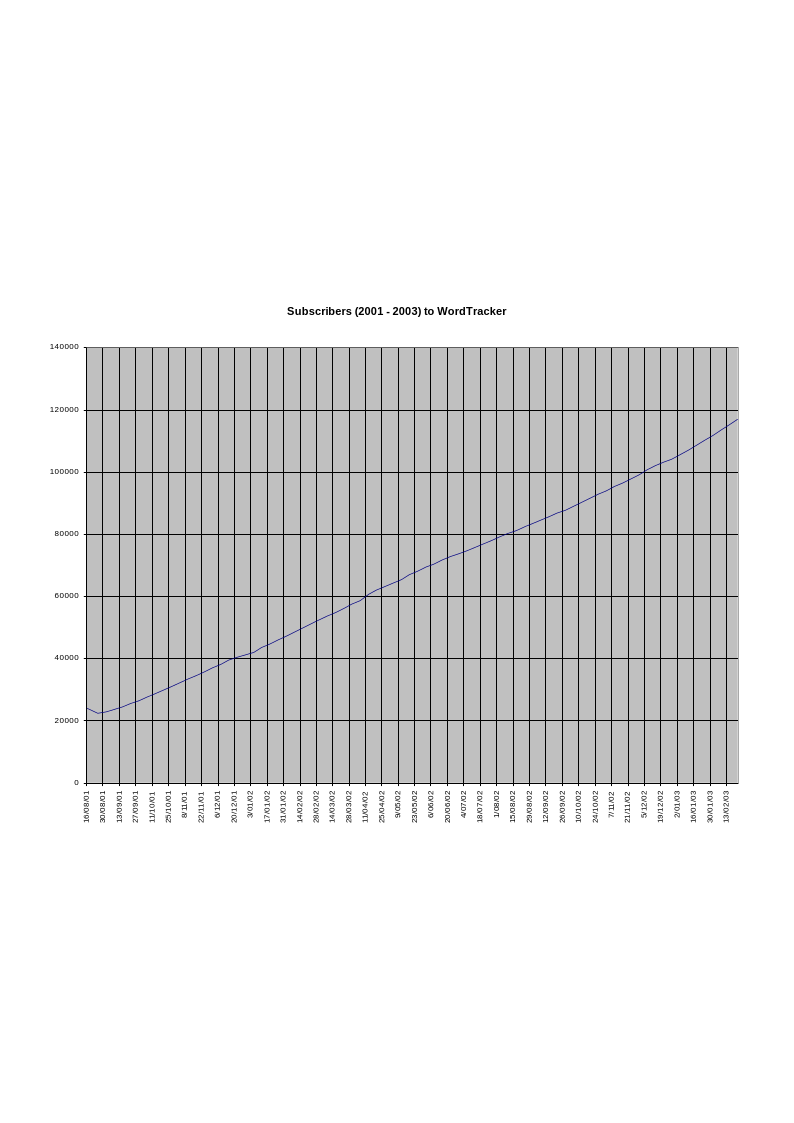
The increasing number of subscribers - documented in each newsletter - reveals an increasing understanding of the importance of this material. However, the rising popularity of this newsletter has the danger of producing a feedback loop on the data collection process when subscribers ‘test’ top ranking terms. The list is associated with the wordtracker.com Web site as a free ‘teaser’ for their commercial services. Wordtracker.com claim that their services help to locate commonly searched for keywords that are appropriate for a paying client’s Web site but have very low or no bids at popular pay-for-placement search engines. It is claimed that the cost of the service is offset for the client by more targeted Web site traffic and a reduction in expenditure incurred from bidding at the pay-for-placement search engines. This work does not make any assessment regarding these claims or whether the stated benefits are actually produced by this service as this is beyond the scope of my current research.
The list of search terms is gathered by wordtracker.com from a meta-search engine - while it is not stated, MetaCrawler is the most likely candidate - and is based upon the individual searches undertaken at this engine. The list as it is currently sent out is separated into two parts. The first part is a list of 300 words that represent surges of immediate interests. These are the words that have been the most popular searches in the last 24 hours. The second list consists of 200 words that are the most sought after terms over a four week period.
The rationale for keeping the origin of the search terms secret is claimed by the editors of the list is to prevent an unscrupulous subscriber from boosting particular words by robotically conducting hundreds or thousands of searches that would promote their own interests at these sites. Search terms ‘boosting’ activities do occur and can be evidenced in the popularity of the terms ‘qxapoiu’ and ‘beneauver’. Both terms have been described as ‘search engine spam’ as they do not appear to have any defined meaning (Perkins n.d.). However, this observation may be the result of a lack of specific cultural capital on my own and others behalf. The number of searches necessary to appear on the surge term list can be quite low. Consequently a series of searches generated in response to seeing these words in a film, a photograph, another Web site or in print - or in the list of the “Top 500 Search Terms” newsletter - may be sufficient to constitute it as a ‘legitimate’ surge search term.
Search engine spam (Perkins n.d.) is a more complex phenomena that does not appear to offer directly commercial or other benefits from the use (or supposed search engine popularity) of a nonsense word. The benefits of search engine spam to the spammers is also unclear and not directly related to the presence of a particular term in the “Top 500 Search Terms” newsletter. Spamming the list of popular terms may work in a negative sense by forcing other ‘legitimate’ terms out of the list. This action decreases the interest in the term from other bidders and potentially allows the spammer to make lower bids on legitimately and formerly popular terms. The other possibility is that the apparently increased popularity of a term will increase the value for bids on these terms at pay-for-placement search engines. However, the only clear beneficiaries for these activities would be the pay-for-placement search engines themselves and then only if the nonsense term was actually used in a search - a seemingly unlikely combination of actions. Perhaps the most likely explanation for the search engine spam in the gathered data is the presence of automatic robots that have been directed to test the values necessary to appear in data relating to Web activity. Search engine spam would, in this way, provide a base or null value from which other more ‘sensible’ terms can be quantitatively compared. The number of robots currently operating on the Web cannot be directly quantified and their actual individual purposes are equally diverse. The readily availability of robot software in various guises, particularly wget and curl, enables computer users with even the most rudimentary skills to run robots from their own internet-enabled computer. This type of ‘system’ testing activity has precedence among virus and worm developers who regularly release software that will test new algorithms or camouflage techniques ‘in the wild’ of the Internet. For example, the prevalence and impact of the SoBig worm (BBC 2003a) through 2003 and into 2004 was increased because the anonymous author(s) continually released new versions as they learned from the behaviour of the previous versions. Arguably these releases were also based on a competitive spirit with authors of other viruses (TechStuff 2004).
An initial collection of weekly lists was gathered for this research between March 2000 and December 2000. In this set of weekly data there are two separate lists. The first consists of the top 500 keywords and the second list consists of 20 surge words. Unfortunately the initial data was edited at its source - the “Top 500 Search Terms” newsletter - to remove the ‘adult’ concept words. The second set of weekly lists was then gathered from August 2001 until February 2003. However, only two lists were received before the events of the 11th September 2001. The format of the lists from these two initial weeks reflects the style and format of the earlier 2000 dataset. The list that was received on the 14th September 2001 followed a different format with a list of 300 surge words and only 200 consistent performers. The newsletter then consistently used this format until February 2003. These latter lists all included ‘adult’ terms and were unedited. The second subsequent set of weekly lists forms the basis for the discussions in this work. The first edited set of lists was used primarily to assist the research design and to create the classification software that was subsequently applied to the second set of search terms. This first set of data is included as Appendix 1 (on the attached CD).
Alongside the ranking of each search term in the lists is a ‘count’ value. This represents the number of times a search was actually conducted for this term. These count values reveal the relatively low numbers of searches that are needed to gain inclusion on the surge list and implies that the number of unique searches conducted each week must be a seven digit number. To gain first place on the surge list in a ‘normal’ week takes approximately 2500 separate searches. The 300th place is filled by terms generally searched for less than 250 times. The significant anomaly captured by the dataset of the 14th September 2001, immediately after the terrorist attacks of September 11th, shows that the top surge term, ‘osama bin laden’ was represented by over double the ‘normal’ number of searches, 5826. Variations on the capitalisation of the name also appear at 3rd and 5th position with each raw ‘count’ values higher than a ‘normal’ first placed surging search term. Other variations on the spelling of this name also appear throughout the surge list. This is a significant observation as the aftermath of the terrorist attacks is reflected by more individual searches in this period, which are specifically about the attacks. The ‘usual’ search terms - the terms interpreted by this research in the context of desired artefacts and cultural traits - are still present. Ten days after 11th September the surge list still reflects heightened activity on the search engines but with a shifted emphasis. ‘Nostradamus’ and its variations fill the 1st and 8th place while terms such as ‘World Trade Center’, ‘Insurance’ and ‘American Flag’ also occupy positions in the top 10 of the surge list. The impact of the attack was already waning, however, as the more usual surge words such as ‘hotmail.com’, ‘hotmail’ and ‘yahoo’ had already reappeared in the top 10 of the surge list. By the 29th September, ‘Hotmail’ was at the top of the surge list followed by ‘Hotmail.com’, ‘Yahoo.com’ and ‘google’. ‘Sex’ also reappeared in the top 10 of the surge list as the sixth most popular terms, juxtaposed between ‘world trade center’ and ‘gas masks’.
Within the longitudinal perspective of this data, the events of the 11th of September present an anomaly. Other events of significance captured and represented in the datasets are of a lesser scale and are found in more consistently sought out and desired classes. The terrorist attacks are an extreme event, the surge list of keywords tends to reflect a more consistent set of shifting and immediate concerns. Events that cause the most dramatic shifts in the surge lists are generally influenced by a combination of factors including annual holidays and the mass media at both international and national (primarily US) levels.
To borrow a commonly used term from the Web itself, the “Top 500 Search Term” newsletter is a type of meta-data. The data gathered from this source represents a cross-section of the mainstream of human interests. There are a number of cautions that must be acknowledged in using data gathered from this type of source. The data does not offer any demographic or geographic detail that could enable a more sensitive ethnographic identification of the people who have generated the searches that have, in turn, been consolidated into the lists of terms. Lack of further context restricts the range of observations that can authoritatively be drawn from this data. However, this is not an impediment to the current project which, by utilising a taxonomic approach, is making use of a generalising methodology that is seeking to present a systematic and verifiable overview of cultural beliefs, events and traits rather than an direct ethnographic representation. As my research centres upon artefacts and their relationship to contemporary cultural practices the generality of the lists provides a framework for this understanding.
A factor that cannot be identified from the data provided by the received lists of search terms is the individual number of times that a single person has conducted the same search at the same search engine over the period of a single week. This may appear to be a trivial observation but there is a possibility evidenced in the weekly surge lists that as there are relatively small count values and small differences in the count values between individual items one person of their own volition could readily propel a term into a weekly list. Evidence from the activity logs of the meta-search engine that I developed in a professional context indicates that a single person will occasionally conduct the same search at the same site many hundreds of times within a short space of time. Personal communication (pers. comms Top-Pile, Internet World North, Manchester, 6th November 2003) with employees from a ‘web placement’ agency has also revealed that these agencies often conduct many - possibly hundreds - of searches for their clients’ specified key terms. The rationale for this activity was not made clear in my personal communications as one search would be sufficient to establish a client’s position. However, this activity may relate to search engine spam as increased search activity on a term may raise the metric used by these companies in their communications with their clients. The count values of individual entries in the search term lists must not therefore be considered as an absolute indicator of human activity but rather an indicator that incorporates indefinite values of ‘perseverance’ and ‘marketing’. In this way, a single person who is motivated - for whatever motivation and by whatever means - to search for the same term repeatedly during a single week generates the same level of significance for a particular term as that of many people searching once for the same term in the same period. While consistently and clearly misspelled words in the lists would suggest that this is the situation the available data provides no means to confirm this speculation. As a reflection of these indeterminate but unsubstantiated concerns no adjustment of the count values has been made to represent this possible influence. An assumption has had to be made that for the most popular search terms there is a constant percentage of all terms that is generated in these types of ways. The consistent reappearance of the same terms and the consequently observed consistency of the distribution of terms between the nie main classificatory classes would suggest that if this influence does exist it also occurs consistently from week-to-week. It is a factor that can only be acknowledged.
A definite influence on the count values in the lists, and one related to the previous point, is the presence of Web robots. These are semi-automatic pieces of Internet capable software that traverse the Web with little or no human intervention beyond the initial instructions bound into their software. The presence of these robots has already been acknowledged as a possible factor for the presence of ‘search engine spam’. Some Web robots are ‘well-behaved’ and leave a site when asked, do not visit dynamic sites such as search engines or directories and do not take too much information from a single site in any single visit - this good practice is formalised as the “Web Robots Exclusion Standard” (www.kollar.com/robots.html). Other Web robots do not behave. In the parlance of the Unix operating system they are not ‘nice’. They will not identify themselves to the Web site accurately, often masquerading as a ‘normal’ version of Internet Explorer, they will take too much data in a single visit, they will visit search engines - sometimes indefinitely and infinitely - and they will not leave politely. Web robots have been primarily used by search engines to check and gather material for their databases. Even these Web robots are not necessarily well behaved - Altavista’s scooter and the Opentext robot have gained notoriety for being particularly aggressive and persistent (Stein 1998). The caution that must be exercised in terms of the data collected from the “Top 500 Search Terms” newsletter is revealed by the documented behaviour of a Web robot caught in a loop and repeatedly sending the same query to one of the earliest Web-enabled large scale database (Stein 1996). Most Web robots, even badly behaved ones, will eventually give up but not until 100, 500 or more duplicate searches have been conducted. While Web robots are clearly themselves interesting examples of ‘virtual’ artefacts, worthy of discussion and investigations, their presence does disrupt the interpretations that can made of the “Top 500 Search Terms” newsletters. The compilers of this list do claim that this influence has been removed from their data but without detailing the methods for this exclusion. The influence of robots on search term popularity cannot be quantified directly, it is, in any event, an indirect indication of a human determination to locate specific items online. The difficulty in quantifying the impact of these actions is partially located in the fact that the human motivation for sending out a Web robot is less specific - and potentially more damaging - than a person themselves conducting multiple searches for a single term. Web robot’s are human ‘tools’ invented to reduce direct human labour and increase the rapidity with which a mundane task can be completed. The increasing prevalence and availability of Web robot tools also makes any interpretations regarding the human purposes for their presence indefinite. Ultimately, Web robots do not impede the claims made by thesis because as artefacts they themselves are immured within the culture being discussed.
While these cautions are ever-present concerns throughout these discussions, the regularity and even monotony with which the same keywords appear in the consistent performers list in roughly the same position suggest that the impact of these all these issues on the formation of the list is relatively consistent and more importantly a legitimate aspect of the culture that these search terms reflect. More positively, and irrespective of these issues, the “Top 500 Search Terms” newsletter is a unique resource for researching the interrelationship of the desire and seeking of artefacts with cultural traits and contemporary culture in an environment where change is rapid.
Data and Initial Site Examination
The data from the “Top 500 Search Terms” newsletter is considered with three separate perspectives in order to offer a range of interpretation informed by the constructed taxonomy in Chapter 5. The first perspective is provided as a direct consequence of the consolidation that occurs when the data is classified through the use of the Universal Decimal Classification system. The UDC’s advantage as a decimal system is the capability to present different orders of magnification. A snapshot impression of the weekly data can be seen by viewing the volume of keywords within each of the nine top level orders of classification in the UDC. Each of these classes can in turn be examined individually down to the detail of individual classifications. This offers potentially minute detail with up to nine hundred classes, the use of decimal points for further divisions and the capacity to group and associate multiple classes together. In these initial discussions of the data the focus is initially upon the entire classificatory scheme. More detailed examinations are then presented regarding specific classes of the classificatory scheme where terms are densely clustered or where apparent anomalies have appeared in the collated and classified data. The data is represented visually throughout this work using two-dimensional bar charts. Figures 3 & 4 show visual representations of the top-level classes of classified data utilising the set of ‘surge’ and ‘consistent’ keywords received on the 22nd February 2003. This set incorporates ‘adult’ terms and is the last week of data I have used for the current project. Developing this view of the data brings together conceptually associated terms that appear separately in a variety of forms in the list. The most conspicuous duplications in the original data are found in the variations of domain names. In the consistent list for the 22nd February 2003, ‘yahoo’ (ranked 5th), ‘yahoo.com’ (rank 12th) and ‘www.yahoo.com’ (28th) all appear but in a classificatory sense these are unambiguously a single item. Similarly ‘google’ (4th), ‘google.com’ (51st) and ‘www.google.com’ (63rd) are also treated as a single item. Considering these terms together, as representing a similar meaning and intent for the searcher, have the impact of making ‘yahoo’ the most searched for term in the list. However, in most other situations the terms are separate entities despite their classificatory similarities in the terms. For example - in the consistent list of the 22nd February 2003, ‘song lyrics’ (26th), ‘music’ (31st) and ‘Free Download Music’ (61st) appear to be similarly associated set of terms. The use of the Universal Decimal Classification scheme associates terms sufficiently to reflect a related intent and meaning within the ‘7’ class - Arts and Entertainment.
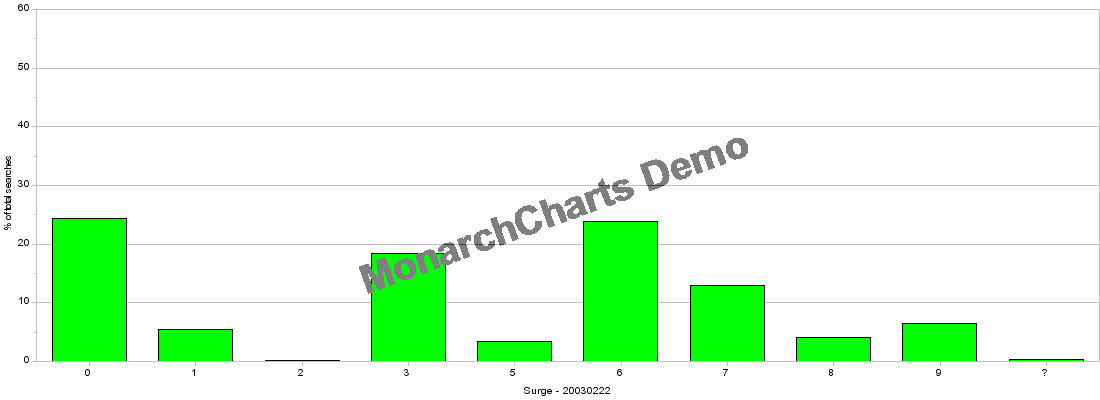
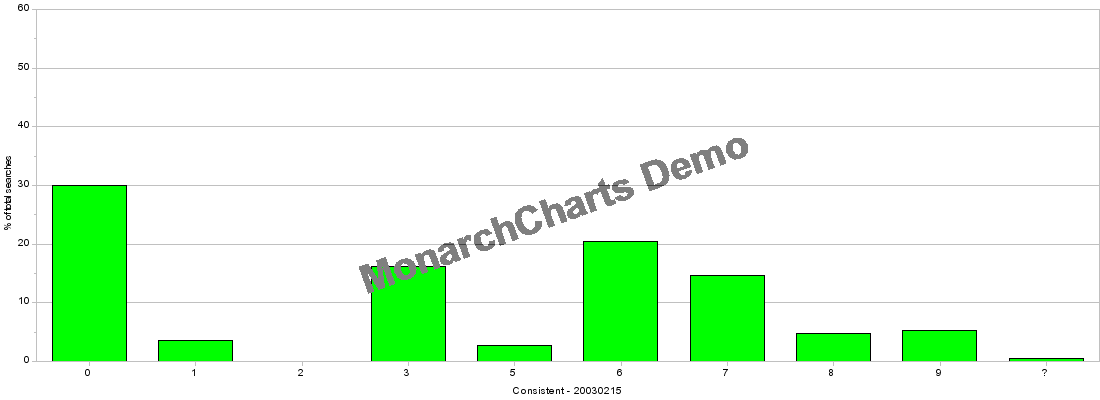
The data also presents a series of keywords that cannot be classified by the UDC system employed for this research. In most cases these terms are nonsensical (in this context) single characters such as ‘l’, ‘a’, ‘h’, ‘k’, ‘j’, ‘g’, ‘m’, ‘f’ and ‘d’. While these characters may have meaning in specific contexts, this is not conveyed through the data and these terms are consequently classified with a ‘?’ - effectively outside the scope and capabilities of the classification scheme. It is also impossible to ascertain from the information available whether these searches, if they are meaningful at all, share the same context between individual searches. It is almost inconceivable that in the case of the letter ‘l’, 19428 searches could be generated accidentally in one week of data (14/09/2001). Only the vaguest physical (three key) proximity on UK, Australian and US keyboards to the ‘Enter’ key can offers some - very tentative - explanation but it is difficult to imagine any other reason for its prevalence. It could equally be suggested that the shock of the terrorist attacks prompted many individual but hurried searches. The data from the “Top 500 Search Terms” newsletter do not reveal the number of times the semi-colon or single quotation mark are searched for and all the ‘punctuation only’ search appear to have been deleted from the newsletters before they are distributed. However, collecting data on these searches may actually provide regionalised information as the keyboards in the UK differ from those in Australia and the US. In this way a more expansive collection of data could distinguish between searches for the ‘@’ and the single quote and make a strong argument for the proportionate use of a search engine by UK users (or at least those people making use of the UK keyboard layout). It is also an important curiosity of some possible significance that with the exception of ‘m’, all of the individual ‘character’ search terms are positioned on the centre row of a standard QWERTY keyboard. The otherwise unexplainable collection of characters reflects the way that the keyboard produces specific types of artefacts. The use of dummy or test passwords such as ‘qwerty’ or ‘asdf’ that employ a continuous string on the keyboard is discouraged by IT security advisors (Yan et al 2000) as it is a known password often used by hackers to gain access to a system. In a similar manner, single letters may also reflect some type of individual testing of a search engine. The final possibility for character searches returns to a common argument for these various anomalies. A single letter search may be used as a dummy value to test the capacity of a search engine - a common letter such as ‘a’ will reveal whether the search engine imposes any upper limits on the number of results that are returned for any specific search. Single letter searches may also reveal whether a search engine searches for individual strings of characters or word by word. While this is a subtle distinction, knowledge regarding this type of information is important for a Web site to secure a good position in a search engine’s results. A single letter search also has the ability to reveal ‘bugs’ and weaknesses in a search engine that could be exploited by hackers.
The second perspective on this data is a temporal view offered by presenting the week by week shifts in the focus of interest and use of the Web by users of the search engine that provides data to the “Top 500 Search Terms” newsletter. These changes can be traced through both the weekly short-term surge lists and those of the long-term performers. Tracking these changes allows a representation that reveals shifts - or otherwise - in popularity between different classificatory classes and at the same time the relative volume of searches conducted in a specific week. A selection of search terms is examined over the duration of the collected data. These terms act as indicators that reveal the volatility of interests and the stability or otherwise of terms within the lists. These movements trace the rise and fall in popularity of particular phenomena, events and people. This charting also reveals particular cultural obsessions and traits as they manifest themselves on the Web. The resultant indices of contemporary culture are used to consider the extent to which this material offers an indicator of mainstream cultural activity and can represent particular cultural formations and particular cultures.
The final perspective used to examine this data explores the movement of individual keywords and groups of keywords over the data collection period. A graphical representation is also employed for this perspective. For example, Figure 6 shows the movement in popularity of the third level class - 343 - that covers criminology and all forms of crime. The criminology class is not itself particularly unusual and rather is an indication of the sort of fluctuations in popularity over time that are identifiable in the collected data. Tracing shifts in search term interest over time reveals factors such as the current season and the impact of mass media on the level of interest generated at a search engine for, for example, a film or an individual celebrity.
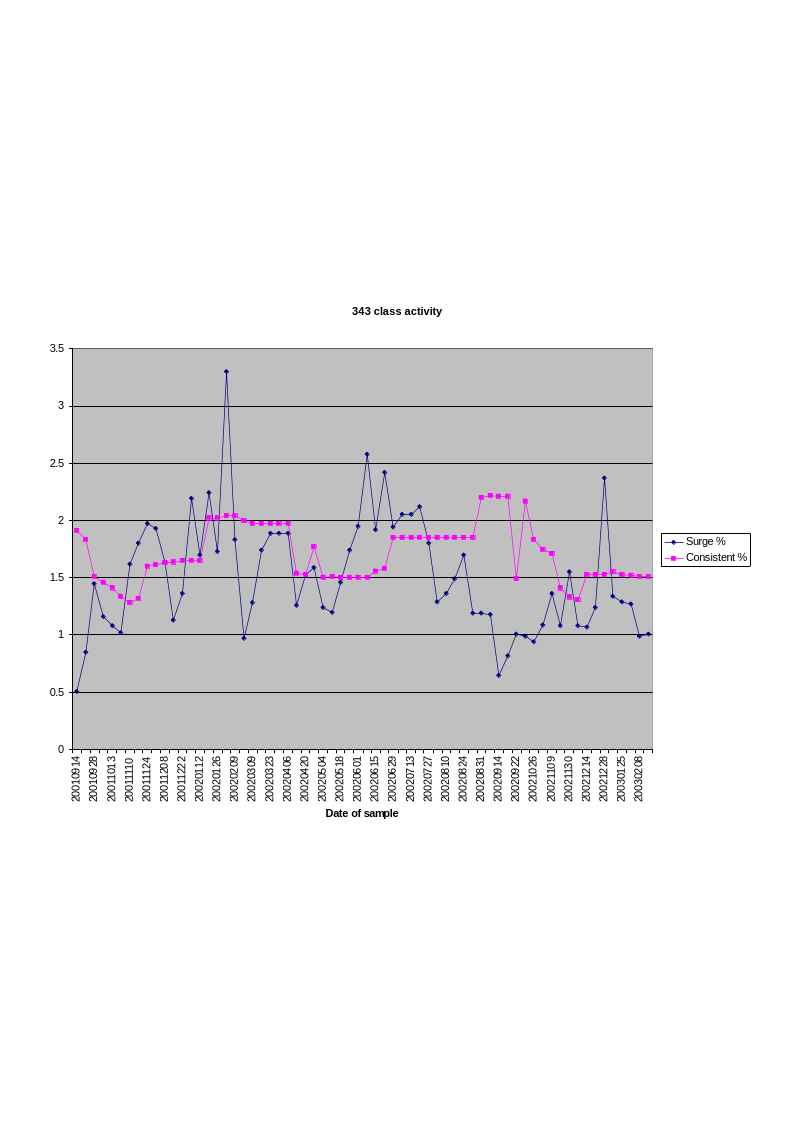
In each of these three perspectives the raw count values provided by the “Top 500 Search Terms” list is the basis for this gathering up of the data. This readily enables a revised popularity ranking to be offered that utilises percentages and classificatory classes rather than the count of individual search terms used by the original data. Comparisons between the search term list of individual weeks are also possible with these percentage-based rankings. There is a week to week variation in the total number of searches enumerated in the lists and this justifies the use of a percentage in the diachronic examination of the data. Variations in the weekly popularity of searches are not a specific focus of this research but this variability is acknowledged by the use of percentages instead of the rankings assigned in the original newsletters.
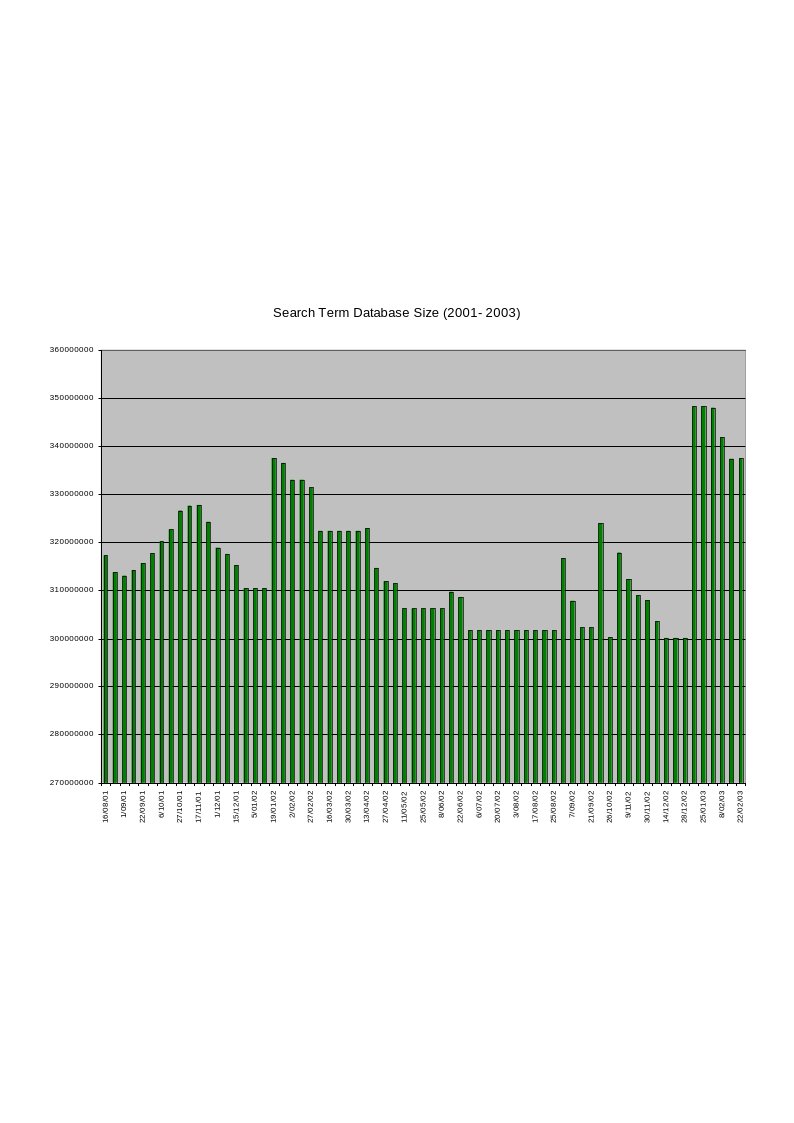
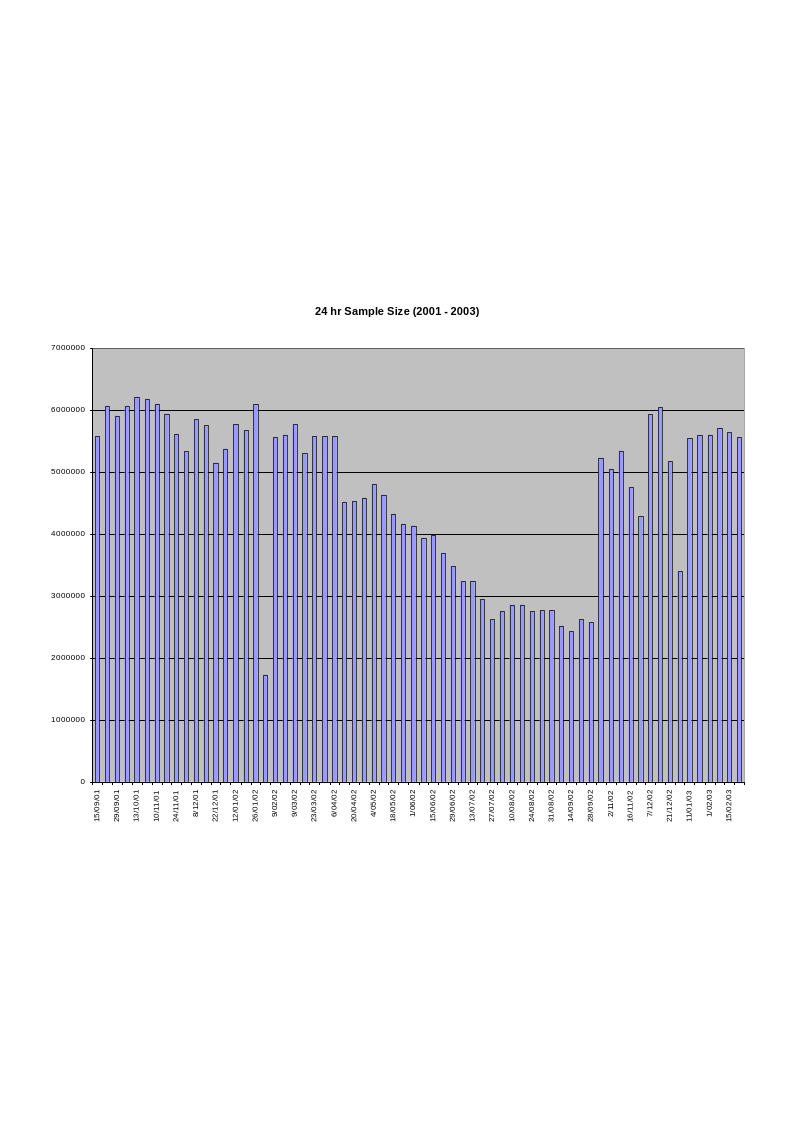
The initial examination of the data involved classifying individual terms within the Universal Decimal Classification scheme. Terms that were ambiguous or could be allocated to multiple orders were classified in each order utilising the extension (the + symbol) syntax of the UDC. Terms that could not be classified at all were left unclassified - this is indicated with the ‘?’ symbol. However, every effort was taken to classify each term and in each week’s data the level of ‘unclassifiable’ material was minimal. The first week of unedited lists received in September 2001 was the initial basis for this classification. This data is not included as part of my resultant discussion, however, as the format of the report was not consistent with subsequent weeks. To ensure the consistent application of the classification scheme from week to week this initial classification of a term was then applied to the reappearance of the same term in subsequent weeks. New terms that appeared in new lists were classified with every attempt made to keep these classifications consistent with earlier classificatory decisions. Utilising software to identify and manage new terms also enabled the consistent application of classification decisions across both the surge list of terms and that of the consistent performers. As classification is a subjective activity every effort was made to keep the rationale for the assignment of terms to individual classes consistent. Maintaining the classification of an individual term between lists and across all the weeks of the gathered data ensures - at the very least - that if a term is ‘mis-classified’ it will consistently appear in the wrong class.
In order to ensure methodological consistency and to note possible anomalies that were revealed a set of running notes was maintained through this process. My notes became the basis for the cataloguing rules of this gathered data. The notes were developed as follows:
- Attempt to provide three levels of classification.
- Attempt to minimise further levels of classification. This is done > to maintain a level of comparability and to bring individual items > together rather than to separate them.
Specific Web site names or addresses are marked with the place > auxiliary - 0.03
The non-UDC auxiliary is used for the apparent form of the target > being sought by the search term.
s = specific location
c = category of items
a = category of actions
i = indefinite or vague target
- Use indexed terms as they are found in the UDC Pocket > Edition (1998) if available.
- Use indexed terms as they are found in the UDC Condensed > Edition (1961) if available and cannot be located in the UDC > Pocket Edition and do not contradict recent changes in the UDC > (i.e. pornography 176.7).
- Use the : extension symbol rather than the + relation symbol - in > order to facilitate the automatic and systematic processing of the > classification data. This implies that the first classificatory > class is weighted to have greater significance. This may have > longer term and negative implications for interpretations and > extensibility of this research.
- Classification prioritises the item over its format (particularly > computer based formats) thus ‘morpheus’ is a form of > exchange (394) that is enabled through software rather than being > a piece of peer-to-peer (exchange) software. This reflects the > focus and the purpose of ‘morpheus’ as a file sharing system over > its specific form.
- Classifications of human groups are not assumed to be > pornographically motivated - this is potentially problematic in > the case of terms such as ‘lolita’ (classified as 3-053.6): a > young woman.
- The UDC lacks the capacity to classify gifting and free exchange - > this results in the use of the 394 class to indicate public/social > life. This classification is overly broad and reflects an unstated > and previously unacknowledged commercial assumption in the UDC > when dealing with these issues.
- The term ‘free’ is problematic for similar reasons as gifting > oriented terms - this distinction is recognised with an (F) in the > non-UDC auxiliary
- People and groups of people are recognised with (P) in the non-UDC > auxiliary.
- Items classified under a slang terms are indicated with the non-UDC > auxiliary, (S). For example, ‘quotes’ was classified as 398.1 C(S) > by assuming that the aim of this search was to gather famous > quotations rather than stock market or commercial quotes. > Similarly ‘pussy’ was classified as 611 C(S) and is founded on the > assumption that this is a slang reference to female secondary > sexual organs. As there is no non-slang root for this word and it > appeared unlikely to be a slang reference to feline house pets the > intention of this search term was relatively clear.
- Items of clothing are assumed to be personal items (646.4) rather > than related to the manufacturing industry (687). This recognises > that the type of apparel generally being sought is specifically > women’s underwear or beachwear. This classification avoids, as > with the classification of types of people, the assumption that > searches for these terms are automatically pornographic in > motivation.
- ‘Counterstrike’ is classified as an aspect of war. However, > counterstrike 1.3 (which includes the version number for a > computer game) is classified as a piece of software. The > popularity of this game is revealed by the regularity that the > term appears in the lists and this would suggest that the more > generic term is being applied in this narrower context. However, > this is by no means certain and cannot be assumed in a post-911 > short-term environment where a counterstrike response to the > terrorist attacks received popular support among the US public.
- ‘MSN Hotmail’ is classified as being synonymous with email. The > ‘hotmail’ aspect of the term is given preference over the more > generic MSN trademark. This classification more clearly reflects > the presumed intentions of those searching for this term.
- ‘Gay Gallery’ is classified as a non-specific request for > pornography. The term ‘gallery’ is heavily and consistently > associated with requests for pornographic material rather than any > specific art galleries. The only exception to this consistent > association of terms is in relation to clipart. Such an > association - in this case - with a more simplistic form of > imagery appears unlikely and unevidenced by the results returned > from major search engines.
- ‘Rose Red’ is classified as television programme - as it was > broadcast at the same time as the surge that was recorded. This > specific association appears to be valid, as the term would > otherwise be classified as a colour and in this context would be > singularly unique. No other colour or variation of colour appears > in any of the gathered lists. The consistent demand for > television, film and entertainment generally throughout the > research period and the strong coincidence between the showing of > the programme in the US and its appearance in the data support the > rationale for this interpretation.
- As Spanish terms some words existed outside my own general > knowledge: ‘Dónde noticias hoy’ and ‘chistes’ (2/2/02). These > terms were some of the few that were not English language search > terms.
- The term ‘qxapoiu’ appears to be a form of search engine spam. This > argument is made with specific reference to the data used here at > both http://www.qubez.co.uk/insider/qxapoiu/ & > http://www.aaxis.com/qxapoiu.htm. This supposition is also > applied to the term ‘beneauver’ - > http://www.google.com/press/zeitgeist/weeks-feb03.html.
- While ‘Daniel Pearl’ is clearly identified as a journalist who was > executed as an accused spy the comments and underlying message > made at the Web site > http://home.nyc.rr.com/janegalt/Videotapes.htm is somewhat > unclear in this context. There may be a more specific and clearly > articulated story associated with this person and the use of his > name as a search term.
- Some terms were virtually unclassifiable. Examples of these problem > terms include ‘elin’, ‘rims’, ‘the big game’ (which is probably a > lottery - but there are too many possibilities to be entirely > definite), ‘Music City’ (which also has too many possibilities but > is probably related to filesharing and the morpheus peer-to-peer > client. Searches for ‘musiccity.com’ were classified within this > context.), ‘John Nash’ (too many people but the most probable > reason for this search is the name of the main character of the > film about John Nash), ‘Daisy Cutter’ (probably a reference to a > ‘hi-tech’ bomb but also it is also a band and other ‘things’), > ‘Lowes’, ‘ana’ (but is most probably related to Pro Anorexia) and > ‘it’ (ambiguous by being too specific). In most cases, the problem > was not that the term was too vague but that by being so > specific - in the searchers framework of understanding at least - > too many possible alternatives were available.
- ‘none’ is left unclassified, as this may be the result of a search > engine’s programmatic response to a blank query. Similarly, > ‘blank’ is also classified in this way for the same reasons. Both > terms are also concepts not readily classified in isolation within > the UDC scheme.
- ‘Dave Thomas’ is assumed to be the founder of Wendy’s as the surge > of interest in the name came after his death. The relative lack of > any other ‘Dave Thomas’ in search results at sites like > google.com and altavista.com offers > few other explanations.
- ‘Klingle Mansion’ is classified as a building although the real > interest that is reflected by its search popularity is in the > murder that was committed there. This classification is clearly > problematic as it appears to reflect a popular media description > of the case and this overtly emphasises the place of the murder > rather than the action, the perpetrator or victim.
- ‘rock creek park’ is classified as a park although it was the site > of the discovery of the murdered body of Chandra Levy. As with > Klingle Mansion, this representation is deceptive by focussing > attention on the locale of the murder and not the attack or the > victim.
- ‘Kazza’ is assumed to be ‘kazaa’. This single misspelling appears > 202 times in a single week. This misspelling is commonly made on > Web sites promoting KaZaA software however its sudden appearance > cannot be directly explained from the available data.
- Although ‘WxDataISAPI’ is a system file in the Windows operating > system it is classified with hacking as this is the point of its > interest. An identified weakness in this particular file was > publicly announced with the expectation that those with an > operating system that included this file would update it.
- The term ‘snr0ncam1 jpg’ only appears to relate to the > wordtracker Web site and the data that it produces. > While it appears to be some form of file name related to a webcam > or a specific software package no conclusive solution is offered > by searching the major search engines. This term is probably some > type of search engine spam that may have the intention of > ‘tricking’ searches related to images to a particular Web site.
- ‘scripts’ is assumed to refer to programming and programming > languages rather than film or television scripts. There is no > clear rationale for this classification decision other than the > observation that the general balance of unambiguous search terms > tilt towards a computer orientation rather than towards the > dramatic arts.
- The term ‘update’ presents a similar problem to ‘free’ in that it is > a generic verb when it is treated in isolation. Although the > expected intention for the use of ‘update’ was to locate new > releases of software this was could not be assumed from the > available information and consequently was classified with a ‘?’. > This term - in isolation - could also be treated as a hacking term > as the examination of update and patch software is one means by > which hackers can seek out security holes in unpatched systems.
- From the 10th August 2002 a lot of what appears to be > hacking-related activity becomes evident. This appeared to be a > major shift in the general activity recorded by the search term > lists.
- The term ‘snakehead fish’ appears to relate unambiguously to an > indigenous North American fish and is classified in this way.
- ‘Thong’ is assumed to be an undergarment rather than footwear. The > general interest in underclothing and swimwear in the weekly list > of terms and the generally Australian provenance of the second > meaning supports this position.
- ‘personal checks’ is classified with ‘background checks’ as a form > of investigation. The US spelling of ‘cheque’ could render this > term ambiguous but no other terms related to instruments of > personal banking are included in the lists.
- ‘Masters’ is classified as a ‘degree’ of education while ‘masters > golf’ is clearly a specific tournament. This may reflect my own > academic bias rather than a clear distinction in the intentions of > users of these terms.
The “Top 500 Search Terms” newsletter is compiled by a group based in the United Kingdom - an influence that should be acknowledged. This may influence a distorted representation of the data. The animated cartogram of web users traced by Global Lab (www.globalab.org/eng/) indicates and then predicts that over time and with increased penetration of communication and computing technologies the base population of a nation will become the major determinant for the national number of Internet users. The Cybergeography web site provides a variety of visual representations of this situation as well (www.cybergeography.org/atlas/census.html). While a conscious effort is made to consider African and Asian nations the general theme confirmed by this material is the historical predominance of the United States and Europe. The data and particularly the most popular search terms continue to reflect the influences of mainstream US media culture. Hollywood and the major US record labels dominate searches for films or music. Slang terms are also inevitably US or UK-inspired. The Web has even been disparagingly labeled as the United States Wide Web (U.S.W.W.) by less celebratory commentators of the phenomena (Fischler 2000; Agre 2002). Such a disparaging observation is a reference to the heavy bias on many of the most popular sites (which are largely based in the United States) to their domestic audience and their TV-like style. These commentators acknowledge in various ways that the relationship of the Web to individual national cultures is not universal or necessarily positive. This is similarly the direction of Miller and Slater’s argument in their work concerning the Internet and Trinidad (2000).